

本文认为,GPT-5 的重大进步在于其“混合模型”架构,实际上是一个“路由器”,这使得 OpenAI 在单位成本智能方面处于领先地位。文章认为,实现具有成本效益的智能本质上是一个路由问题。这个路由器概念,是从混合专家 (MoE) 演变而来,允许 GPT-5 动态地将查询定向到专门的子模型(例如,推理模型与非推理模型)。作者强调了关键优势:能够独立开发和调试不同的模型组件,并通过模型的“统一化”简化用户体验。虽然开发人员通过新的参数保留了精细的控制,但最终用户在模型选择方面面临的认知负担较小。文章表明,这种混合方法并非秘密,而是领先的人工智能实验室中的一种常见策略。
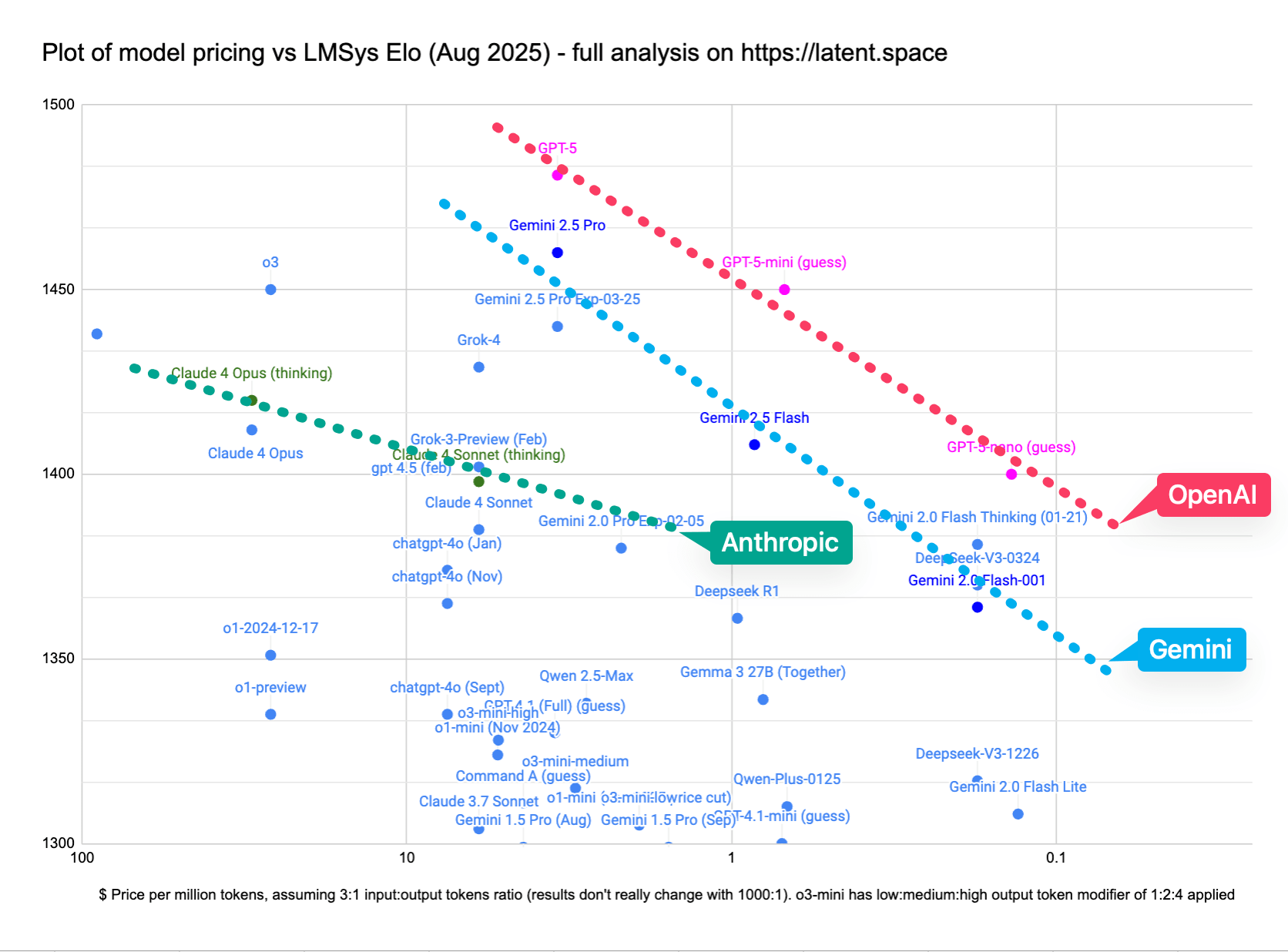
We have been the most vocal proponents of the intelligence pareto frontier since the start of the reasoning model era. Demis took note and GDM went for it. But with GPT-5, OpenAI now dominates the intelligence per dollar frontier for the first time.
When we first tried it out, those of us in the developer beta were initially concerned - “it’s a great coding model… but is that it?” was kind of the unspoken elephant in the room. Sentiment turned more positive over time and the big aha that got me fully hyped was the pricing reveal.
This is because the $ per intelligence frontier is ultimately a routing problem; one that has been a developing and increasingly optimized story since the introduction of GPT-4 and o1.
The #1 question that people have about GPT-5 being “unified” is “is it a router??”, a question I have asked both Greg Brockman and Noam Brown, and after a lot of back and forth on Twitter and inconclusive answers, we now have the answer right there in the GPT-5 system card:
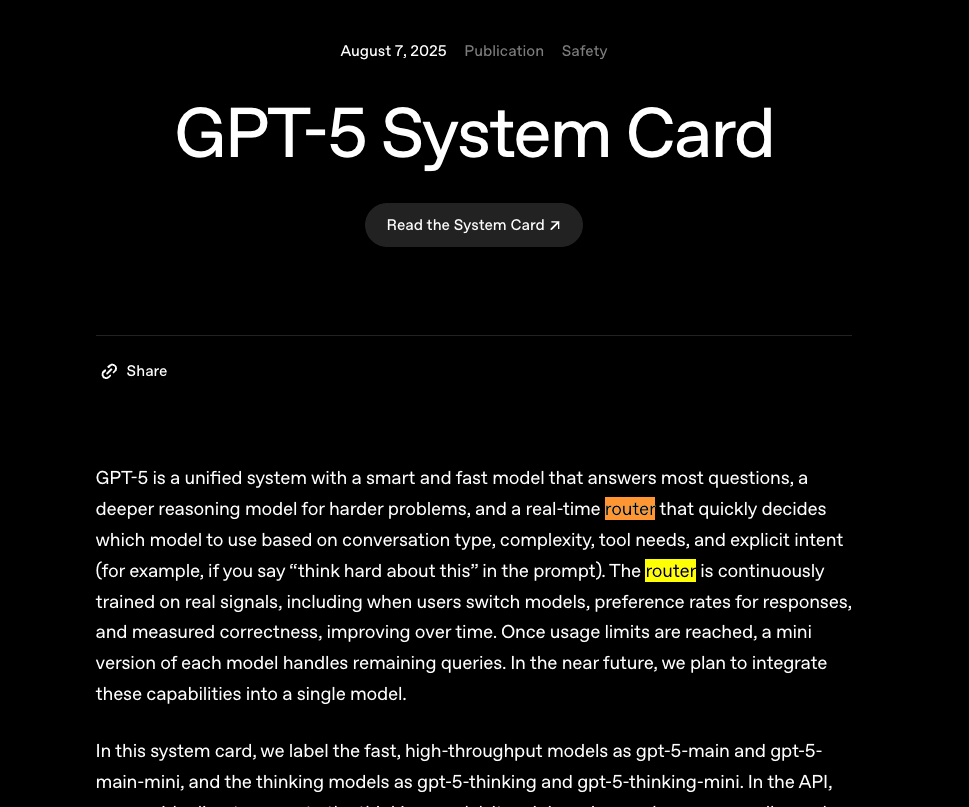
This is a level of transparency I had been asking for from the team, but was never really optimistic about getting!
To really drive it home:
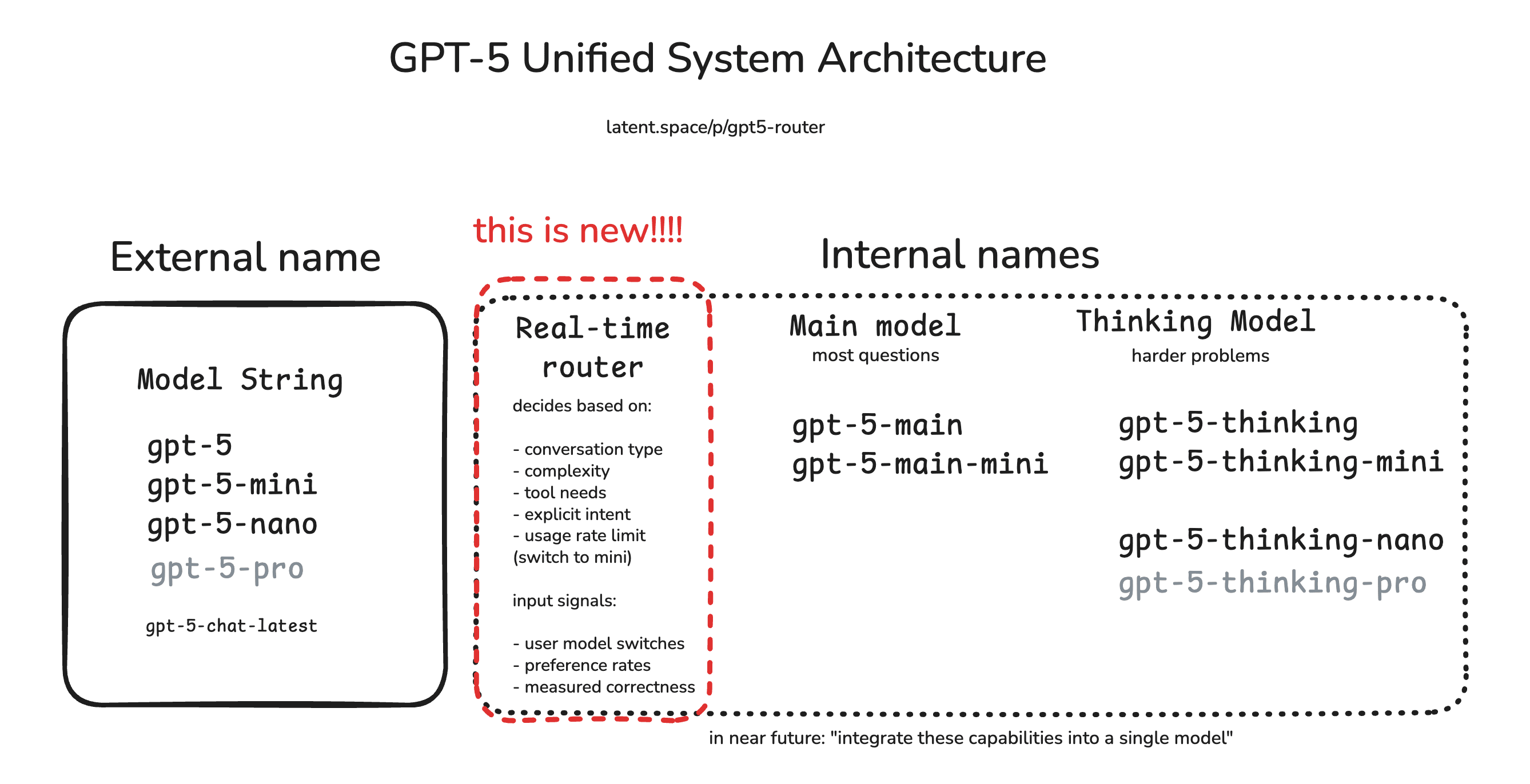
If the big breakthrough from GPT-3 to GPT-4 was the Mixture of Experts, then perhaps the big breakthrough from GPT-4o/o3 to GPT-5 is the Mixture of Models (aka the “router”).
Why does it matter?
To some extent, whether or not GPT5 is a “unified model” or “unified system”, whether or not there’s a component that you call a “router” point blank, doesn’t quite matter. The moment you have reasoning and non reasoning modes, the moment you have different paths for inference for efficiency or specialization (“experts”) or compute depth1, you essentially have a router somewhere in the system, and now it is just a question of semantics and “thickness” of the router layer.
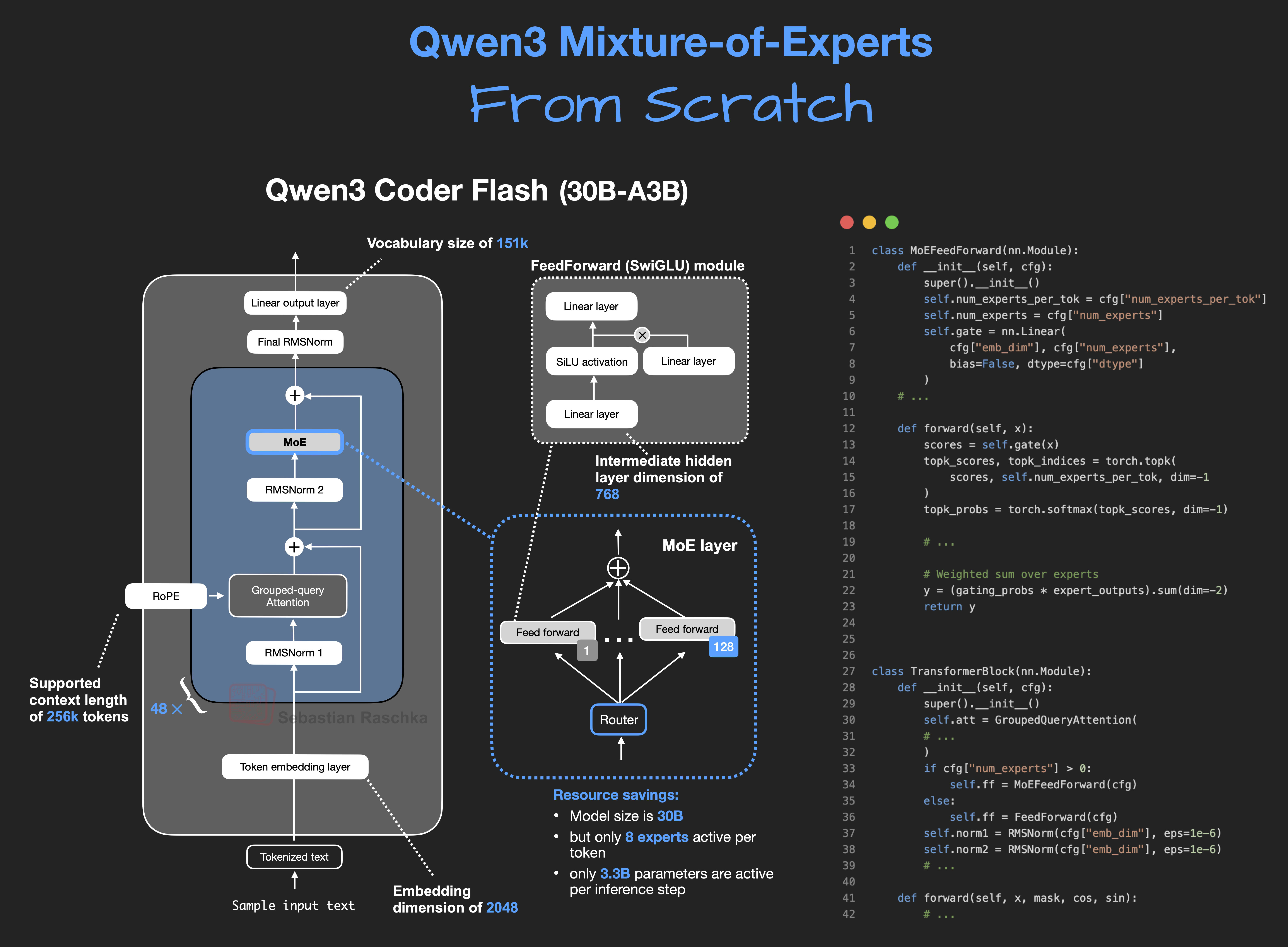
For example you can see the MoE layer in open source models like Qwen 3, where it is clearly routing.
So even though there’s DEFINITELY a router, one benefit and reason why people are still extremely curious about it is the ability to lock down parts of the model performance and independently progress them.
So for example, if GPT5 = router + “new 4o” + “new o3”, then (if we had control of the weights) if a bug happened there are only 3 sources of error:
-
did it route to the right model?
-
if it was a nonreasoner bug, can we fix that?
-
if it was a reasoner bug, can we fix that?
And because these are “orthogonal” independently moving pieces, you can expect that improving one while holding the other constant is an intuitive important step to engineering better AI systems.
Perhaps most comforting (or disappointing?) to the rest of us non-OpenAI-millionaires is that that’s how we would do this too, and there is no big secret that the BigLabs have been hiding that there is a more Bitter Lesson-y way to make hybrid models.
The Great Consolidation
The immediate benefit of the GPT-5 launch is a question of cognitive load - as you can tell the model picker mess weighs heavily on OpenAI and a unified system starts to fix it (even though for developers, control remains as the “model picker” effectively shifts into the new reasoning effort, verbosity, function calling params):

This is backed up by impending model deprecations confirmed in release notes:
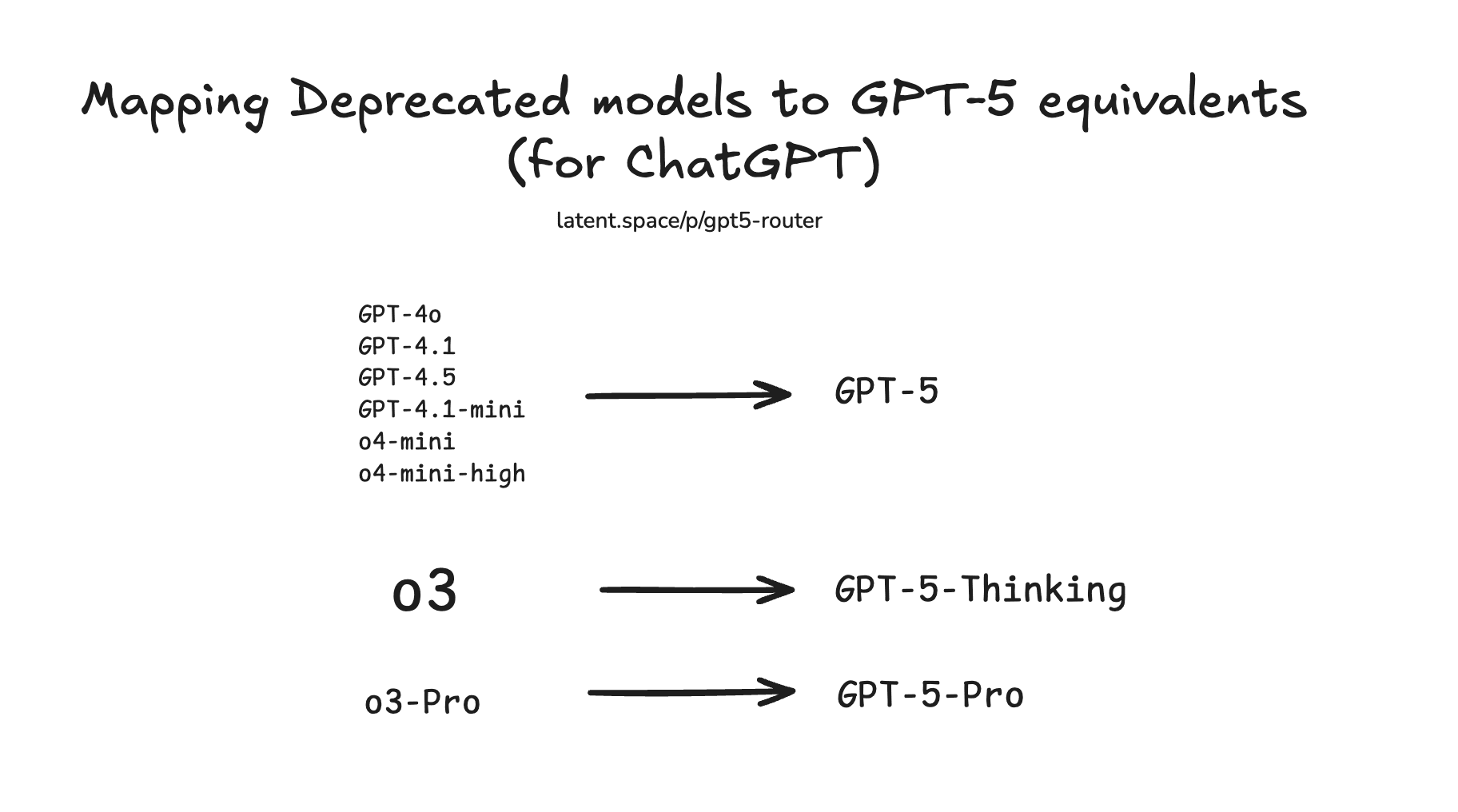
Which is a -far- more ambitious deprecation schedule than the Developer facing options, with all their permutations: