

本文揭示了 T5Gemma,这是一系列基于 Gemma 2 框架构建的新型编码器-解码器大型语言模型。与流行的仅解码器架构不同,T5Gemma 利用一种独特的“模型自适应”技术,将预训练的仅解码器模型转换为编码器-解码器模型。这种方法解决了编码器-解码器架构中未被充分挖掘的潜力,由于其高推理效率和更丰富的输入表示,该架构在摘要、翻译等任务中表现出色。这种自适应还允许灵活的配置,包括“不平衡”模型(例如,一个 9B 编码器和一个 2B 解码器),以微调质量-效率的权衡。实验表明,T5Gemma 模型始终优于或匹配其仅解码器同类产品,在 SuperGLUE 和 GSM8K 等基准测试中占据质量-推理效率的前沿。这种自适应不仅提供了更好的基础模型,而且在指令微调后显着提高了性能。Google 已在 Hugging Face、Kaggle 和 Vertex AI 上发布了各种大小和配置的 T5Gemma 检查点,鼓励进一步的研究和开发。

In the rapidly evolving landscape of large language models (LLMs), the spotlight has largely focused on the decoder-only architecture. While these models have shown impressive capabilities across a wide range of generation tasks, the classic encoder-decoder architecture, such as T5 (The Text-to-Text Transfer Transformer), remains a popular choice for many real-world applications. Encoder-decoder models often excel at summarization, translation, QA, and more due to their high inference efficiency, design flexibility, and richer encoder representation for understanding input. Nevertheless, the powerful encoder-decoder architecture has received little relative attention.
Today, we revisit this architecture and introduce T5Gemma, a new collection of encoder-decoder LLMs developed by converting pretrained decoder-only models into the encoder-decoder architecture through a technique called adaptation. T5Gemma is based on the Gemma 2 framework, including adapted Gemma 2 2B and 9B models as well as a set of newly trained T5-sized models (Small, Base, Large and XL). We are excited to release pretrained and instruction-tuned T5Gemma models to the community to unlock new opportunities for research and development.
From decoder-only to encoder-decoder
In T5Gemma, we ask the following question: can we build top-tier encoder-decoder models based on pretrained decoder-only models? We answer this question by exploring a technique called model adaptation. The core idea is to initialize the parameters of an encoder-decoder model using the weights of an already pretrained decoder-only model, and then further adapt them via UL2 or PrefixLM-based pre-training.
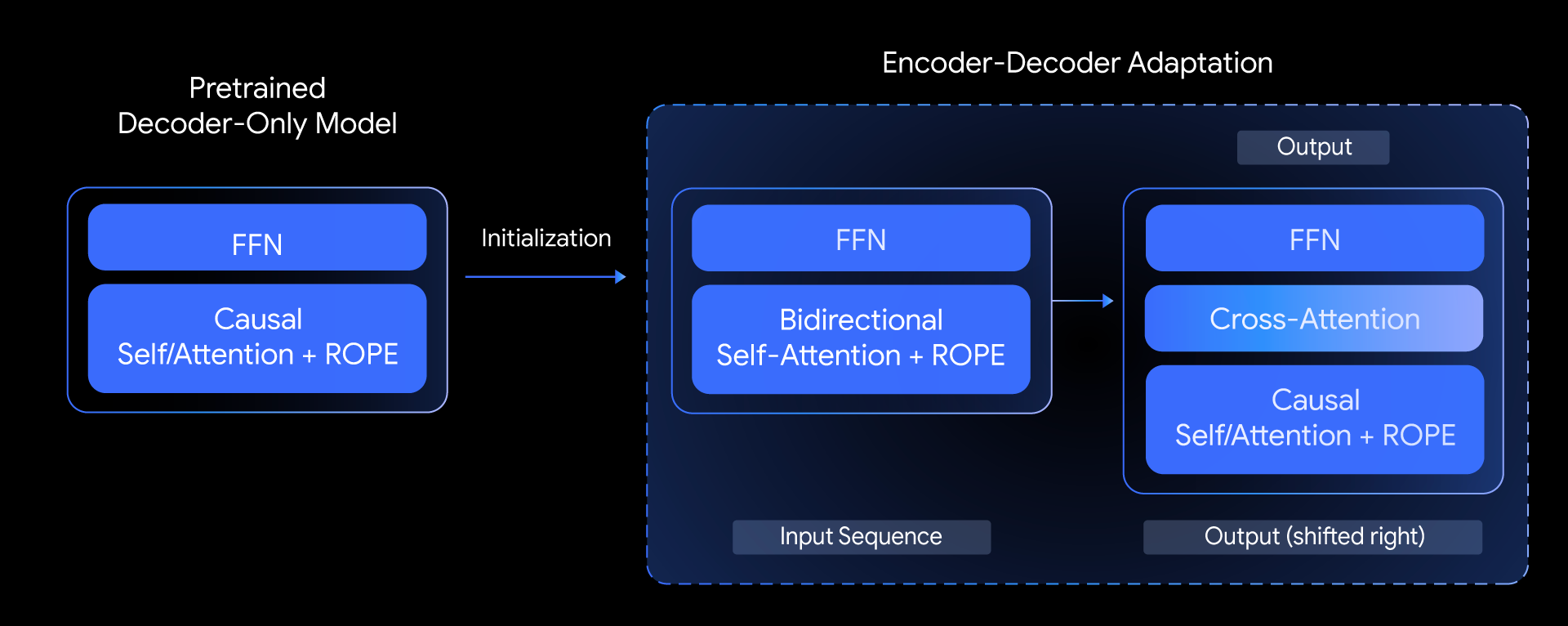
This adaptation method is highly flexible, allowing for creative combinations of model sizes. For instance, we can pair a large encoder with a small decoder (e.g., a 9B encoder with a 2B decoder) to create an "unbalanced" model. This allows us to fine-tune the quality-efficiency trade-off for specific tasks, such as summarization, where a deep understanding of the input is more critical than the complexity of the generated output.
Towards better quality-efficiency trade-off
How does T5Gemma perform?
In our experiments, T5Gemma models achieve comparable or better performance than their decoder-only Gemma counterparts, nearly dominating the quality-inference efficiency pareto frontier across several benchmarks, such as SuperGLUE which measures the quality of the learned representation.
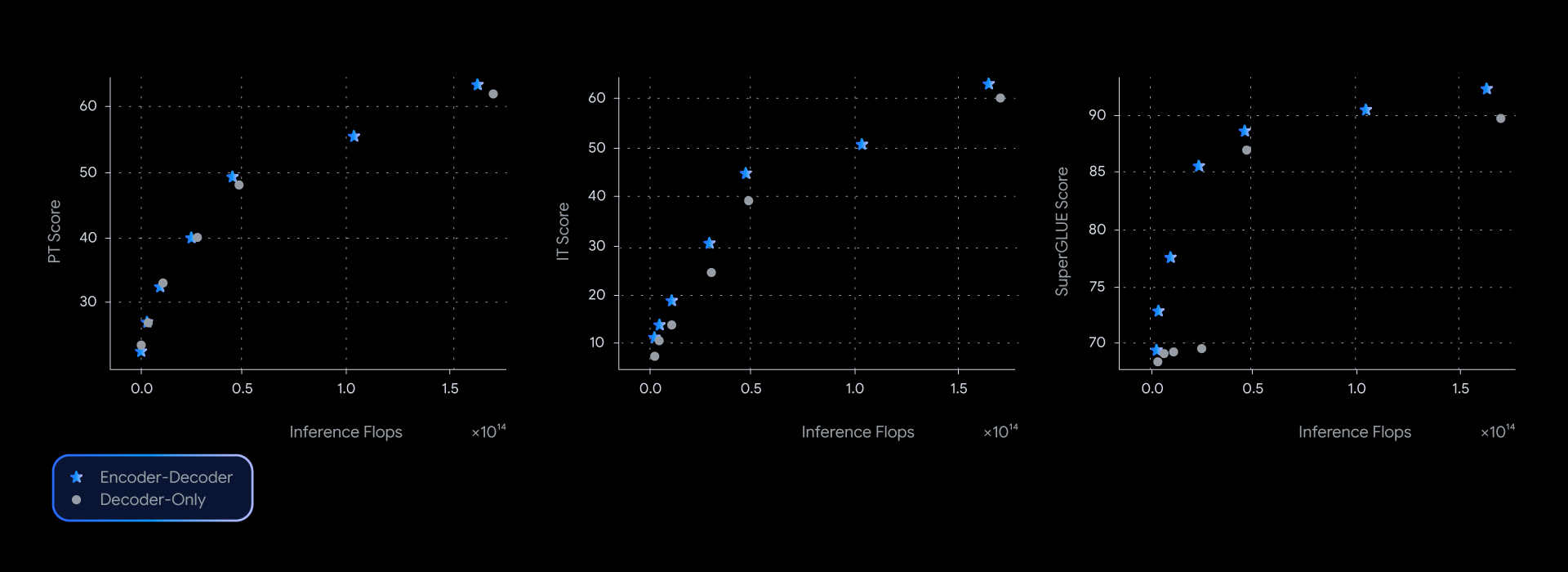
This performance advantage isn't just theoretical; it translates to real-world quality and speed too. When measuring the actual latency for GSM8K (math reasoning), T5Gemma provided a clear win. For example, T5Gemma 9B-9B achieves higher accuracy than Gemma 2 9B but with a similar latency. Even more impressively, T5Gemma 9B-2B delivers a significant accuracy boost over the 2B-2B model, yet its latency is nearly identical to the much smaller Gemma 2 2B model. Ultimately, these experiments showcase that encoder-decoder adaptation offers a flexible, powerful way to balance across quality and inference speed.
Unlocking foundational and fine-tuned capabilities
Could encoder-decoder LLMs have similar capabilities to decoder-only models?
Yes, T5Gemma shows promising capabilities both before and after instruction tuning.
After pre-training, T5Gemma achieves impressive gains on complex tasks that require reasoning. For instance, T5Gemma 9B-9B scores over 9 points higher on GSM8K (math reasoning) and 4 points higher on DROP (reading comprehension) than the original Gemma 2 9B model. This pattern demonstrates that the encoder-decoder architecture, when initialized via adaptation, has the potential to create a more capable, performant foundational model.
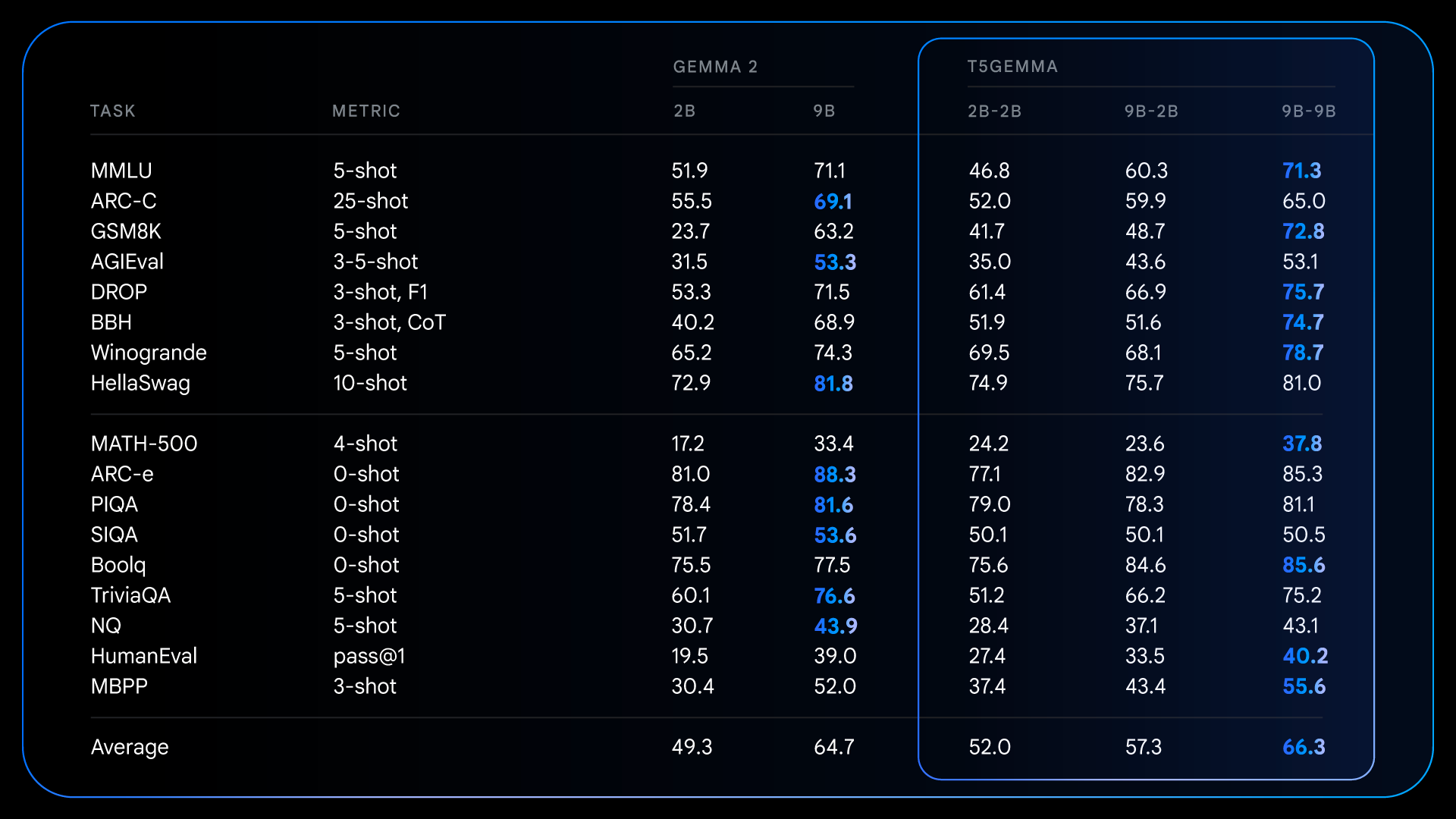
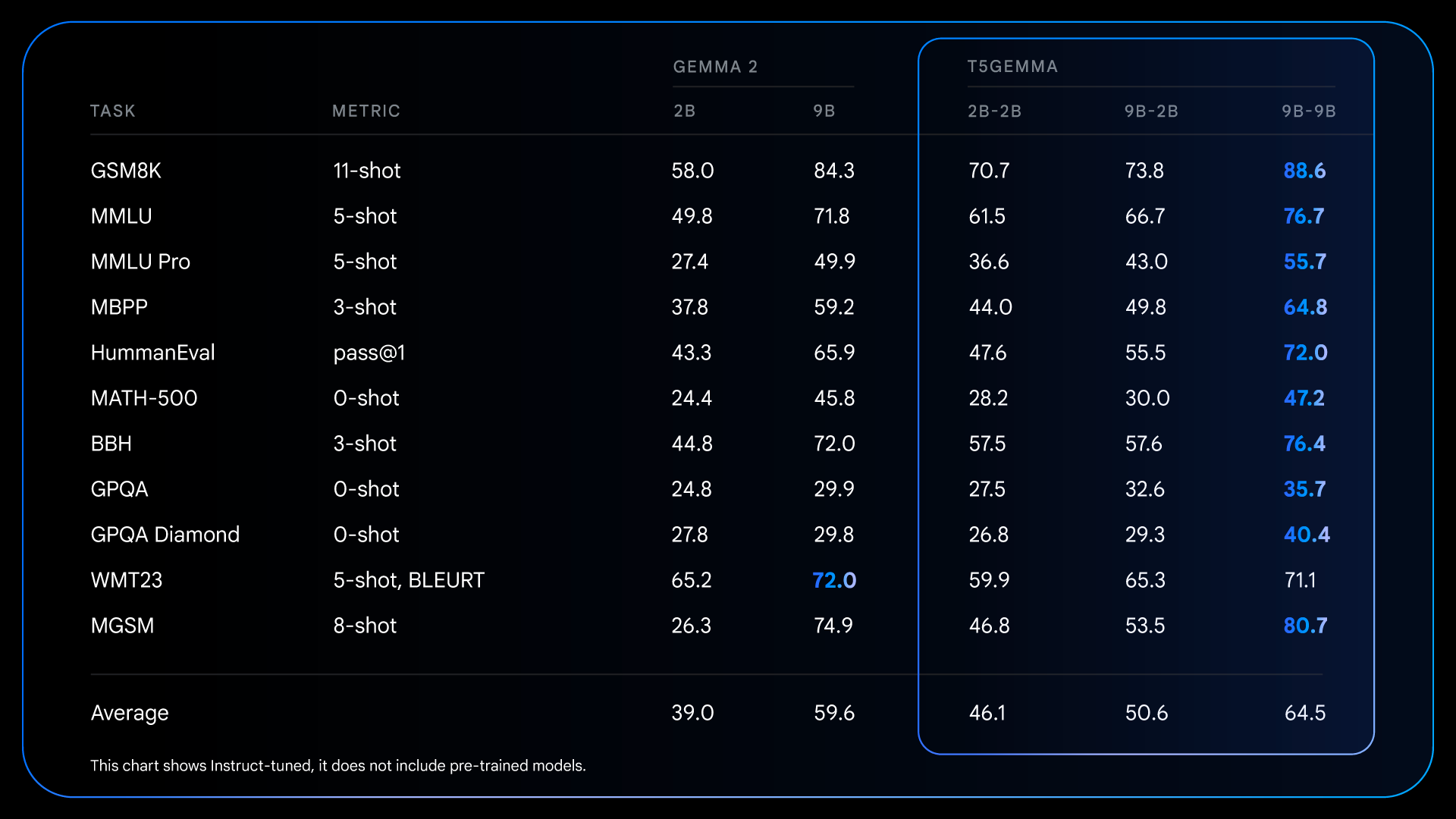
These foundational improvements from pre-training set the stage for even more dramatic gains after instruction tuning. For example, comparing Gemma 2 IT to T5Gemma IT, the performance gap widens significantly across the board. T5Gemma 2B-2B IT sees its MMLU score jump by nearly 12 points over the Gemma 2 2B, and its GSM8K score increases from 58.0% to 70.7%. The adapted architecture not only potentially provides a better starting point but also responds more effectively to instruction-tuning, ultimately leading to a substantially more capable and helpful final model.
Explore our models: Releasing T5Gemma checkpoints
We’re very excited to present this new method of building powerful, general purpose encoder-decoder models by adapting from pretrained decoder-only LLMs like Gemma 2. To help accelerate further research and allow the community to build on this work, we are excited to release a suite of our T5Gemma checkpoints.
The release includes:
- Multiple Sizes: Checkpoints for T5-sized models (Small, Base, Large, and XL), the Gemma 2-based models (2B and 9B), as well as an additional model in between T5 Large and T5 XL.
- Multiple Variants: Pretrained and instruction-tuned models.
- Flexible Configurations: A powerful and efficient unbalanced 9B-2B checkpoint to explore the trade-offs between encoder and decoder size.
- Different Training Objectives: Models trained with either PrefixLM or UL2 objectives to provide either state-of-the-art generative performance or representation quality.
We hope these checkpoints will provide a valuable resource for investigating model architecture, efficiency, and performance.
Getting started with T5Gemma
We can't wait to see what you build with T5Gemma. Please see the following links for more information:
- Learn about the research behind this project by reading the paper.
- Download the models: Find the model weights on Hugging Face and Kaggle.
- Explore the models capabilities or fine-tune them for your own use cases with the Colab notebook.
- Run inference with the models on Vertex AI.