

本文宣布推出 Gemma 3 270M,这是谷歌 Gemma 系列中的一款新型 2.7 亿参数模型,专为高效且特定领域的 AI 应用而设计。其关键特性包括:具有大词汇量的紧凑架构、极高的能源效率(例如,在 Pixel 9 Pro 上进行 25 次对话仅使用 0.75% 的电池)、强大的指令遵循能力,以及可用于生产的 INT4 感知量化训练 (QAT) 检查点。其核心理念是提倡使用“合适的工具来完成工作”,主张针对特定的、高容量的任务(如文本分类和数据提取)使用微调的、专用模型,而不是更大的通用模型。本文提供了一个 Adaptive ML 使用 Gemma 3 4B 成功进行内容审核的真实案例,并概述了 Gemma 3 270M 的理想用例,强调了成本效益、隐私(设备端)和快速迭代。最后,它提供了丰富的资源,供开发人员下载、实验、微调并在各种平台上部署该模型。

The last few months have been an exciting time for the Gemma family of open models. We introduced Gemma 3 and Gemma 3 QAT, delivering state-of-the-art performance for single cloud and desktop accelerators. Then, we announced the full release of Gemma 3n, a mobile-first architecture bringing powerful, real-time multimodal AI directly to edge devices. Our goal has been to provide useful tools for developers to build with AI, and we continue to be amazed by the vibrant Gemmaverse you are helping create, celebrating together as downloads surpassed 200 million last week.
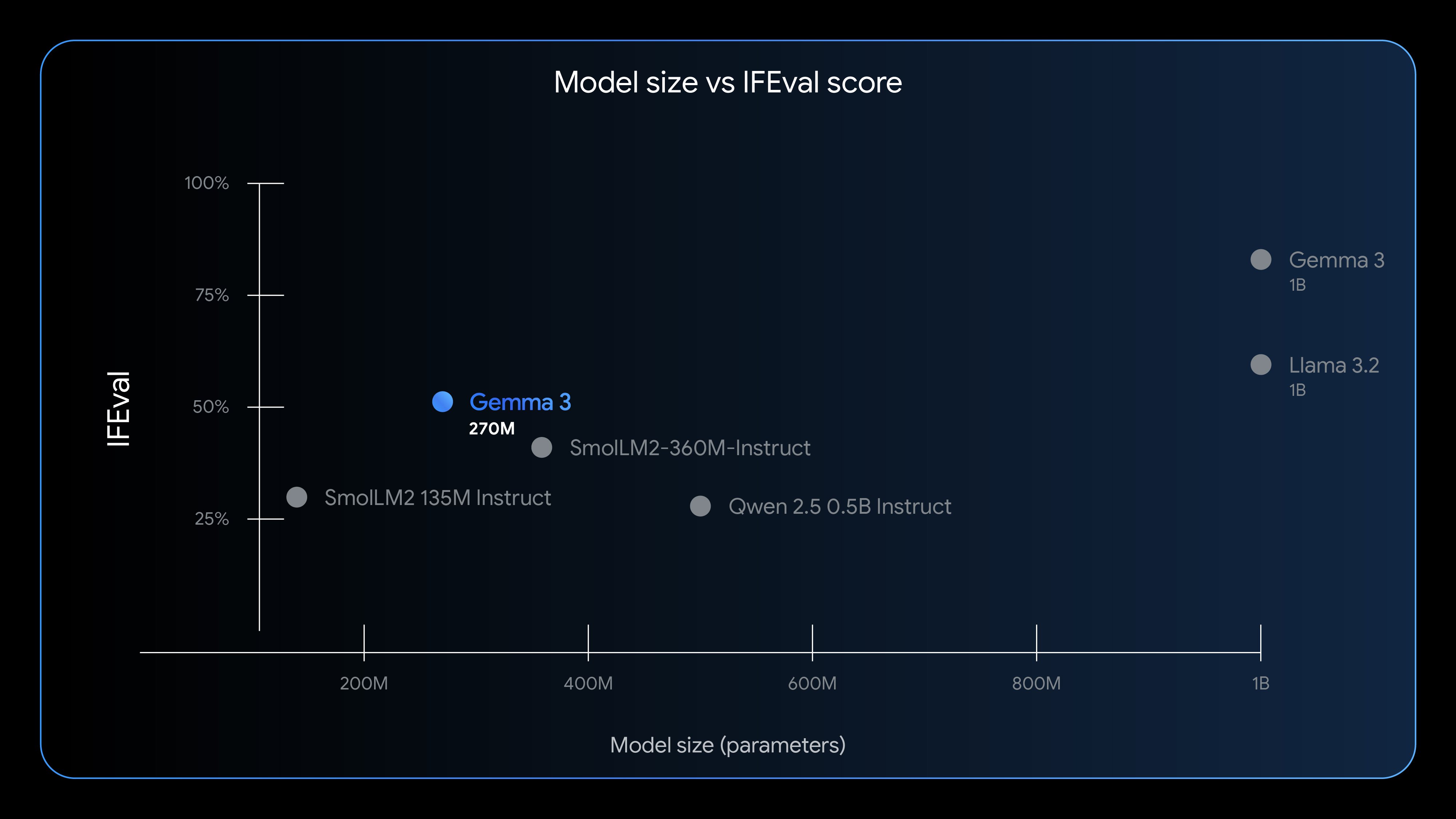
Today, we're adding a new, highly specialized tool to the Gemma 3 toolkit: Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
Core capabilities of Gemma 3 270M
- Compact and capable architecture: Our new model has a total of 270 million parameters: 170 million embedding parameters due to a large vocabulary size and 100 million for our transformer blocks. Thanks to the large vocabulary of 256k tokens, the model can handle specific and rare tokens, making it a strong base model to be further fine-tuned in specific domains and languages.
- Extreme energy efficiency: A key advantage of Gemma 3 270M is its low power consumption. Internal tests on a Pixel 9 Pro SoC show the INT4-quantized model used just 0.75% of the battery for 25 conversations, making it our most power-efficient Gemma model.
- Instruction following: An instruction-tuned model is released alongside a pre-trained checkpoint. While this model is not designed for complex conversational use cases, it’s a strong model that follows general instructions right out of the box.
- Production-ready quantization: Quantization-Aware Trained (QAT) checkpoints are available, enabling you to run the models at INT4 precision with minimal performance degradation, which is essential for deploying on resource-constrained devices.
The right tool for the job
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
A real-world blueprint for success
The power of this approach has already delivered incredible results in the real world. A perfect example is the work done by Adaptive ML with SK Telecom. Facing the challenge of nuanced, multilingual content moderation, they chose to specialize. Instead of using a massive, general-purpose model, Adaptive ML fine-tuned a Gemma 3 4B model. The results were stunning: the specialized Gemma model not only met but exceeded the performance of much larger proprietary models on its specific task.
Gemma 3 270M is designed to let developers take this approach even further, unlocking even greater efficiency for well-defined tasks. It's the perfect starting point for creating a fleet of small, specialized models, each an expert at its own task.
But this power of specialization isn't just for enterprise tasks; it also enables powerful creative applications. For example, check out this Bedtime Story Generator web app:
Link to Youtube Video (visible only when JS is disabled)
When to choose Gemma 3 270M
Gemma 3 270M inherits the advanced architecture and robust pre-training of the Gemma 3 collection, providing a solid foundation for your custom applications.
Here’s when it’s the perfect choice:
- You have a high-volume, well-defined task. Ideal for functions like sentiment analysis, entity extraction, query routing, unstructured to structured text processing, creative writing, and compliance checks.
- You need to make every millisecond and micro-cent count. Drastically reduce, or eliminate, your inference costs in production and deliver faster responses to your users. A fine-tuned 270M model can run on lightweight, inexpensive infrastructure or directly on-device.
- You need to iterate and deploy quickly. The small size of Gemma 3 270M allows for rapid fine-tuning experiments, helping you find the perfect configuration for your use case in hours, not days.
- You need to ensure user privacy. Because the model can run entirely on-device, you can build applications that handle sensitive information without ever sending data to the cloud.
- You want a fleet of specialized task models. Build and deploy multiple custom models, each expertly trained for a different task, without breaking your budget.
Get started with fine-tuning
We want to make it as easy as possible to turn Gemma 3 270M into your own custom solution. It’s built on the same architecture as the rest of the Gemma 3 models, with recipes and tools to get you started quickly. You can find our guide on full fine-tuning using Gemma 3 270M as part of the Gemma docs.
- Download the model: Get the Gemma 3 270M models from Hugging Face, Ollama, Kaggle, LM Studio, or Docker. We are releasing both pretrained and instruction tuned models.
- Try the model: Try the models on Vertex AI or with popular inference tools like llama.cpp Gemma.cpp, LiteRT, Keras, and MLX.
- Start fine-tuning: Use your favorite tools, including Hugging Face, UnSloth, and JAX.
- Deploy your solution: Once fine-tuned, you can deploy your specialized model anywhere, from your own local environment to Google Cloud Run.
The Gemmaverse is built on the idea that innovation comes in all sizes. With Gemma 3 270M, we’re empowering developers to build smarter, faster, and more efficient AI solutions. We can’t wait to see the specialized models you create.