

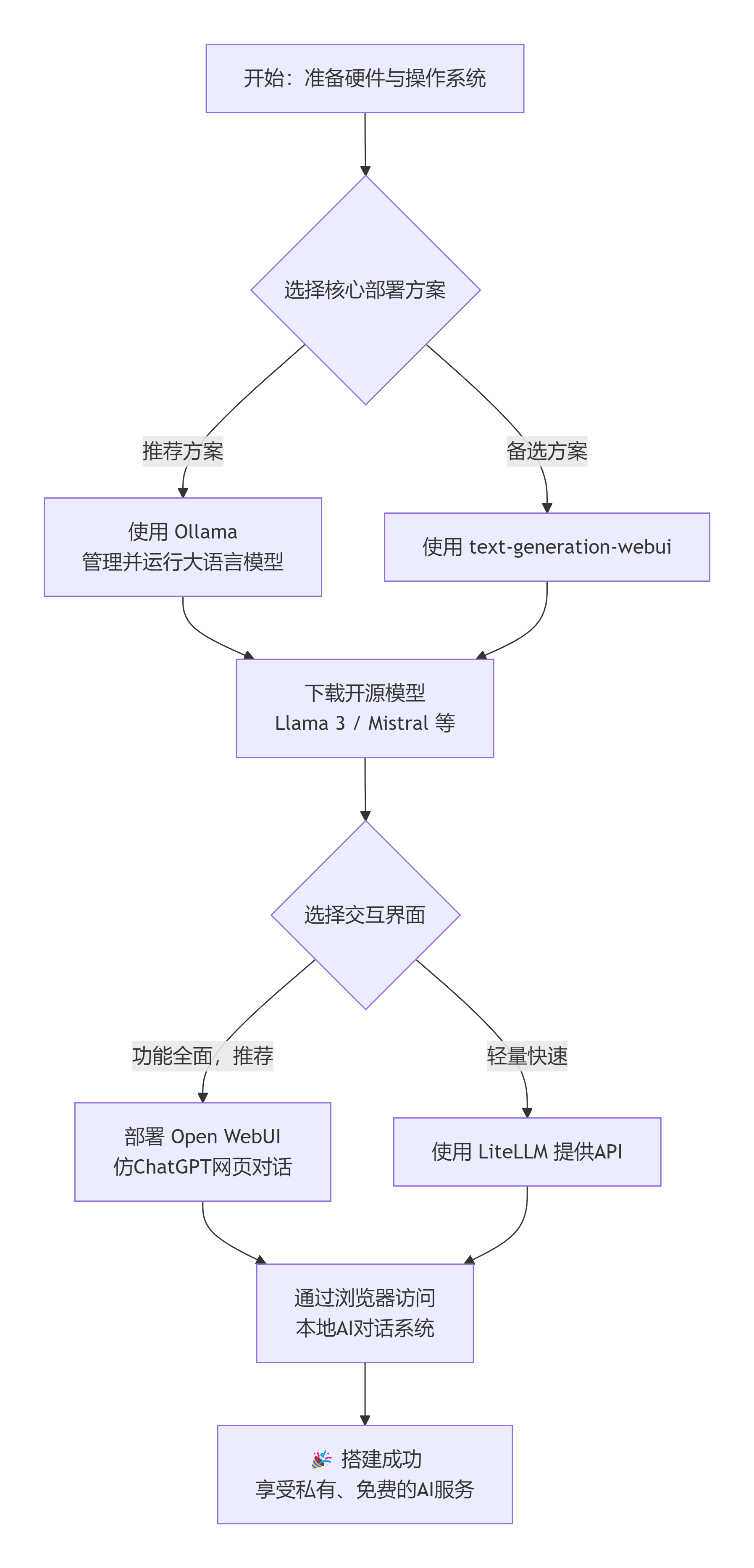
前言:我们能搭建什么?
首先需要明确:我们无法直接搭建OpenAI官方的ChatGPT,因为那是闭源商业服务。但我们可以搭建功能类似的本地AI对话系统,使用开源大语言模型(LLMs),如Meta的Llama 3、Mistral等。本文将带您一步步完成搭建。
准备工作
-
硬件要求
-
最低配置:16GB RAM + 10GB可用存储空间
-
推荐配置:32GB RAM + NVIDIA显卡(8GB+显存)+ 30GB存储空间
-
注意:模型越大,响应质量越好,但硬件要求越高
-
-
软件要求
-
操作系统:Windows 10/11,macOS 10.15+ 或 Linux
-
Python 3.8-3.11
-
Git
-
第一步:安装基础环境
1.1 安装Python和Git
Windows用户:
-
访问 python.org 下载Python 3.10
https://docs.python.org/3/_static/py-logo.png
安装时务必勾选"Add Python to PATH" -
访问 git-scm.com 下载Git
全部默认设置安装即可
macOS用户:
# 打开终端,安装Homebrew(如果尚未安装) /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" # 安装Python和Git brew install python git
Linux用户(Ubuntu示例):
sudo apt update sudo apt install python3 python3-pip git
1.2 验证安装
打开终端(Windows:PowerShell或CMD):
python --version # 应显示Python 3.10.x git --version # 应显示git版本 pip --version # 应显示pip版本
第二步:选择并安装AI运行框架
2.1 安装Ollama(推荐方案)
Ollama是目前最简单的本地大模型运行方案。
Windows/macOS/Linux:
-
安装后打开终端验证:
ollama --version
-
下载模型(以Llama 3 8B为例,约4.7GB):
ollama pull llama3:8b
下载时间取决于网速,请耐心等待
-
运行模型测试:
ollama run llama3:8b
输入"Hello"测试,看到AI回复即表示成功:
>>> Hello Hello! How can I help you today?
按Ctrl+D退出对话
2.2 备用方案:使用text-generation-webui
如果Ollama不兼容您的系统,可使用此方案:
# 克隆项目 git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui # 安装依赖(Windows运行installer脚本) # Linux/macOS: pip install -r requirements.txt # 下载模型(需要先注册HuggingFace账号) # 在模型页面如:https://huggingface.co/meta-llama/Meta-Llama-3-8B # 获取访问令牌后,使用: huggingface-cli login
第三步:安装Web图形界面
本地运行模型后,我们需要一个类似ChatGPT的网页界面。
方案A:使用Open WebUI(功能强大,推荐)
# 确保已安装Docker,或使用原生安装 # Docker方式(最简单): docker run -d -p 3000:8080 \ -v open-webui:/app/backend/data \ --name open-webui \ ghcr.io/open-webui/open-webui:main
访问 http://localhost:3000,首次使用需注册账号:
https://docs.openwebui.com/img/chat_screenshot.png
方案B:使用LiteLLM Web界面
# 安装 pip install litellm # 启动Web界面连接Ollama litellm --model ollama/llama3:8b
访问 http://localhost:8000
第四步:配置与优化
4.1 创建启动脚本
创建文件 start_ai.bat(Windows)或 start_ai.sh(Linux/macOS):
Windows(.bat文件):
@echo off echo 正在启动Ollama服务... start /B ollama serve timeout /t 5 /nobreak echo 正在启动Web界面... start http://localhost:3000 echo 系统已启动!访问 http://localhost:3000 开始聊天 pause
macOS/Linux(.sh文件):
#!/bin/bash echo "启动Ollama服务..." ollama serve & sleep 5 echo "打开Web界面..." xdg-open http://localhost:3000 # Linux # open http://localhost:3000 # macOS echo "系统已启动!访问 http://localhost:3000"
4.2 模型管理
# 查看已下载模型 ollama list # 下载其他模型 ollama pull mistral:7b # 较小,速度快 ollama pull llama3:70b # 质量高,需要大显存 # 删除模型 ollama rm 模型名
4.3 性能优化设置
在Open WebUI设置中调整:
-
上下文长度:4096(8GB显存)或8192(16GB+显存)
-
批处理大小:根据显存调整
-
启用GPU加速(如有NVIDIA显卡):
# 安装CUDA支持 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
第五步:进阶功能配置
5.1 文件上传与处理
Open WebUI支持上传多种格式:
-
📄 PDF/Word文档
-
📝 TXT文本文件
-
💻 代码文件
-
🎨 图像文件(需多模态模型)
5.2 联网搜索功能
# 安装搜索插件 pip install duckduckgo-search # 在WebUI中启用Web Search功能
5.3 语音输入/输出
# 安装语音库 pip install speechrecognition pyttsx3 # 创建语音交互脚本 import speech_recognition as sr import pyttsx3 def speech_to_text(): r = sr.Recognizer() with sr.Microphone() as source: audio = r.listen(source) return r.recognize_google(audio) def text_to_speech(text): engine = pyttsx3.init() engine.say(text) engine.runAndWait()
常见问题解决
Q1:内存/显存不足
解决方案:
-
使用更小模型:
ollama pull tinyllama:1.1b # 仅需2GB内存 -
使用CPU模式:
ollama run llama3:8b --numa -
量化模型(减少精度):
Q2:下载速度慢
export OLLAMA_HOST=镜像地址 # 或使用代理 export http_proxy=http://127.0.0.1:7890 export https_proxy=http://127.0.0.1:7890
Q3:Web界面无法访问
-
检查端口占用:
netstat -ano | findstr :3000 # Windows lsof -i :3000 # macOS/Linux
-
更换端口:
docker run -d -p 3001:8080 ... # 使用3001端口
配置完成效果展示
成功部署后,您将拥有:
-
本地聊天界面:类似ChatGPT的对话体验
https://user-images.githubusercontent.com/1991296/236984325-eb6b2e7a-98df-47dd-8c74-ce6494b7c6c7.png -
多模型切换:根据需要选择不同模型
-
完整历史记录:所有对话本地保存
-
API支持:可连接其他应用程序
资源推荐
-
模型选择指南:
-
入门:TinyLlama(2GB内存)
-
平衡:Llama 3 8B(8GB显存)
-
高质量:Llama 3 70B(48GB+内存)
-
-
学习资源:
安全提醒
-
数据隐私:所有对话数据均保存在本地
-
模型安全:从官方源下载模型,避免恶意修改
-
网络隔离:如需绝对安全,可在完全离线的环境中运行
结语
通过本教程,您已成功搭建了完全自主控制、数据完全本地、永久免费的AI对话系统。虽然当前开源模型在能力上与ChatGPT-4仍有差距,但在日常对话、写作辅助、代码编程等方面已足够实用。
随着开源社区的快速发展,本地AI的能力将持续提升。现在,您可以在 http://localhost:3000 开始您的私密AI对话之旅了!
重要提示:首次运行后,建议创建系统备份点,并定期更新模型以获得更好的性能与效果。
教程中所有软件均为开源免费工具,请遵守各项目的使用许可协议。硬件需求因模型而异,请根据实际配置选择合适的模型版本。