

本文来自 deeplearning.ai 的'The Batch'通讯,涵盖了四个不同的 AI 相关主题。第一部分推广了吴恩达的新课程'与 Andrew 一起构建',旨在教授非程序员如何使用 AI 构建 Web 应用程序。随后的新闻部分深入探讨了先进的 AI 研究和趋势。一个部分描述了 OpenAI 的一项研究,关于微调 LLM 使其在违反指令时'忏悔',从而提高模型透明度。另一个部分介绍了科学上下文协议(SCP),这是一个开放标准,旨在使 AI 智能体能够跨学科进行自动化科学研究,扩展了早期如 MCP 的努力。最后,一项关于 Copilot 使用的微软研究揭示了用户需求以及与 AI 聊天机器人的交互模式如何因一天中的时间、设备类型和随时间推移而大不相同,这对未来聊天机器人设计具有启示意义。
We just launched a course that shows people who have never coded before, in less than 30 minutes, how to describe an idea for an app and build it using AI. It is now time for everyone — marketers, product professionals, operations specialists, analysts, students — to build software applications with AI!
I’ve often spoken about why everyone should learn to code. I’m seeing a rapidly growing productivity gap between people who know how to code and those who don’t. For many job roles I hire for, I now require at least basic coding knowledge. Many times, after I speak with a non-technical audience about the importance of building software using AI, people ask me how to get started. In the past, I didn’t have a great answer. That motivated the DeepLearning.AI team to create “Build with Andrew.” It’s the best way for someone who wants to try vibe coding to get started!
This course requires no prior knowledge of AI or coding. And it’s vendor-agnostic. Specifically, learners can use these techniques with whatever tool they’re most comfortable with (like ChatGPT, Gemini, Claude, or the chatbot built into the DeepLearning.AI platform).
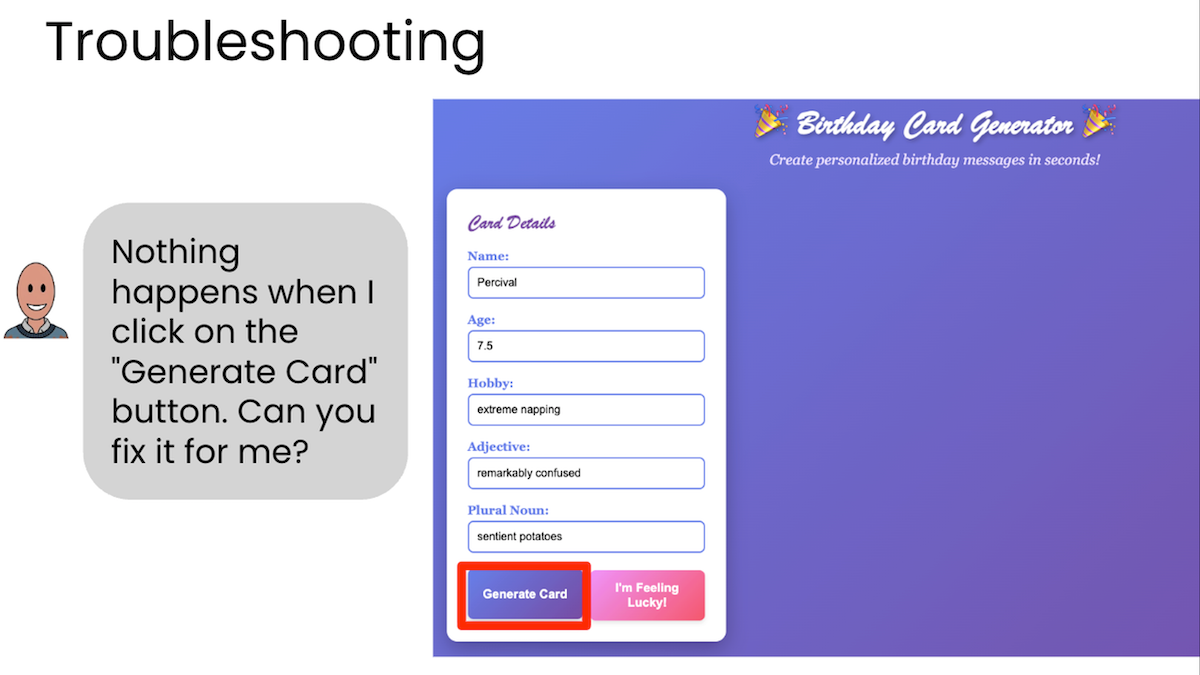
If you take this course, you will build a working web application: a funny interactive birthday message generator that runs in your browser and can be shared with friends. You’ll customize it by telling AI how you want it changed, and tweak it until it works the way you want. By the end, you’ll have a repeatable process you can apply to build a wide variety of applications.
DeepLearning.AI’s mission is to empower everyone to build with AI. This course is just one of many steps in service of this mission.
If you are already a developer, please encourage your non-developer friends to try their hand at getting AI to code for them. Not only will this help their productivity, they will find it really fun as well. Please invite your friends to come build with me!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

You don’t need to learn how to code to build an app. In “Build with Andrew,” Andrew Ng shows how to turn ideas you describe in natural language into working web apps. Perfect for beginners, and easy to share with someone who has been waiting to start. Explore the course now!
News

Teaching Models to Tell the Truth
Large language models occasionally conceal their failures to comply with constraints they’ve been trained or prompted to observe. Researchers trained an LLM to admit when it disobeyed.
What’s new: Manas Joglekar, Jeremy Chen, Gabriel Wu and colleagues at OpenAI fine-tuned GPT-5 Thinking to confess to violations of its instructions or policies. Upon request, the fine-tuned model revealed any transgressions it had committed while producing its most recent response.
Key insight: During training via reinforcement learning to encourage accuracy, style, compliance, and the like, a model may inadvertently learn to prioritize earning rewards over pretrained or prompted objectives. Under some circumstances, this may cause it to hallucinate, lie, scheme, and otherwise misbehave. Rewarding the model for confessing to its misbehaviors in response to a designated prompt should train it to admit its mistakes without affecting its performance.
How it works: The authors used reinforcement learning to fine-tune GPT‑5 Thinking as they normally would, and also to produce confessions.
- An unspecified percentage of the time, given a prompt, the model was rewarded based on its response’s “correctness, style, helpfulness, compliance, safety, and more.”
- The rest of the time, after the model had produced a response, the authors prompted it to produce a confession. The confession described (i) all constraints, instructions, and objectives, implicit or explicit, the response should satisfy, (ii) how well the response satisfied these criteria, and (iii) any ambiguities or uncertainties in the criteria.
- Given the query, response, and confession, an unspecified reward model rewarded the model based on the confession’s completeness and accuracy — a measure of the model’s honesty in confessing, since items that were missing from or falsified in the report can be thought of as lies.
Results: The authors performed 12 evaluations of the model’s ability to follow instructions, resist jailbreaks, produce accurate output, and complete an impossible task (coding a script that required essentially 0 seconds to run). The fine-tuned model, when it misbehaved, confessed to its misbehavior at least half the time in 11 of them. For example, across 5 evaluations for hallucination, it either didn’t hallucinate or owned up to its hallucination 81.4 percent of the time:
- The model did not hallucinate and did not confess 42.2 percent of the time.
- It produced a hallucination and admitted the mistake 39.2 percent of the time.
- The model did not hallucinate but falsely admitted having done so 11 percent of the time.
- It hallucinated but failed to confess to it 2.9 percent of the time.
Yes, but: As the authors point out, even when models are forthcoming, confessions are not a panacea. Models won’t confess to behaviors they don’t know are wrong.
Why it matters: At inference, confessions can be used to monitor a model’s actions and stop undesired behaviors. Chain-of-thought monitoring, which classifies bad behaviors a model might describe in its chain of thought, can be used the same way but, unlike that method, the authors’ approach trains models to reveal misbehaviors they may omit from their chains of thought.
We’re thinking: We always hesitate to anthropomorphize model behavior, but this work may be a step on the path to giving AI models something that resembles a conscience.
Lingua Franca for Science Labs
An open protocol aims to enable AI agents to conduct scientific research autonomously across disciplinary and institutional boundaries.
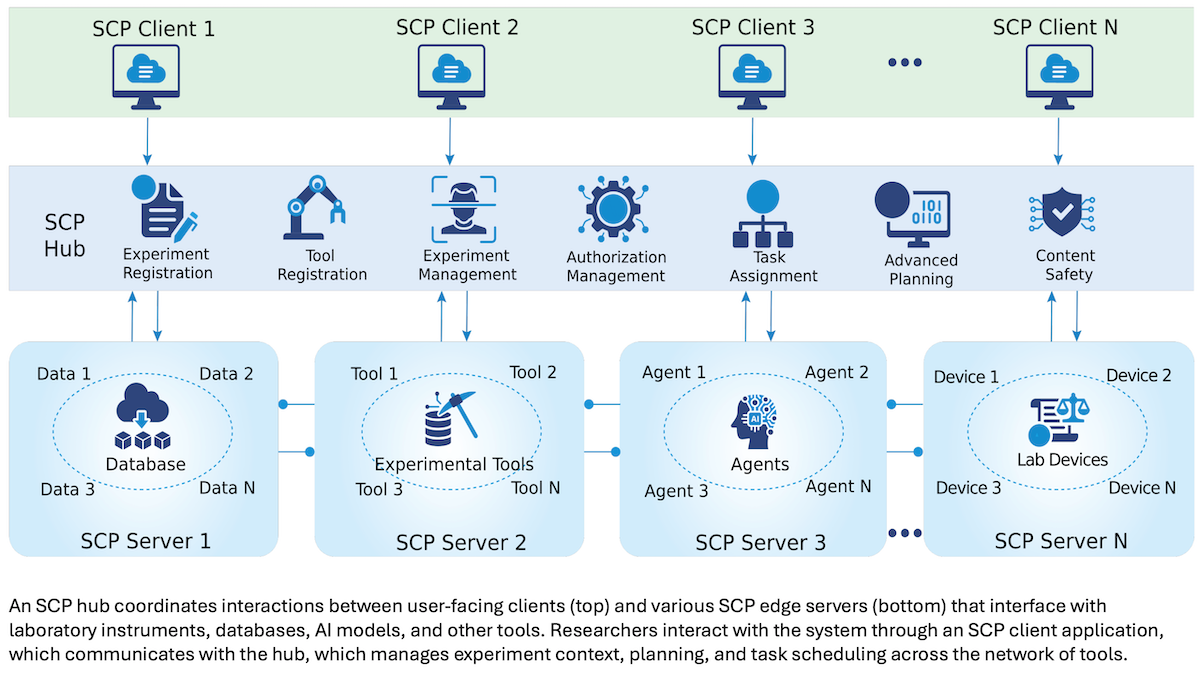
What’s new: Shanghai Artificial Intelligence Laboratory (SAIL) published Science Context Protocol (SCP), an open-source standard that connects agents with local clients, central hubs, and edge servers to conduct automated scientific inquiry. SCP is published under the Apache 2.0 license, allowing commercial use and modifications.
How it works: SCP attempts to make experiments using AI agents and robotic equipment as reproducible as possible. Like Model Context Protocol (MCP), it enables agents to interact with external resources. Unlike MCP, in which servers stand alone, SCP’s design requires centralized hubs that manage other servers as well as the client applications that enable users to access them. In addition, SCP’s structure offers greater security by governing messages and tools more strictly than MCP, which is necessary in scientific experimentation, the authors say.
- SCP’s fundamental data unit is an experiment. Every experiment is stored as a JSON structured data file with a persistent identifier and record of an experiment’s type, goals, data, and configuration. The format makes experiments traceable, versionable, machine-readable, and consistent with institutional policies that govern data.
- An SCP client authenticates users and gives them access to institutional resources. Researchers can describe an experiment’s goal in natural language (for example, “increase the brightness of this fluorescent protein”) or upload a complete research plan in text or PDF for their hub to analyze.
- An SCP hub takes a goal or other request and uses large language models to generate a set of experimental plans that list steps to carry out the experiment. The hub measures and ranks each plan according to its resource requirements, cost, and risk at each step. The user selects one plan, and the hub then orchestrates and schedules multiple agents and servers, which carry out the experiment. After an experiment is completed, the hub archives it for researchers to consult, alter, or repeat.
- Edge servers manage the experiments planned by the hub and stream data back to it (which in turn returns data to the client). Servers may belong to an institution, or they may be devoted to a particular discipline like biochemistry or mathematics, each with its own specialized tools and databases.
- The protocol currently includes more than 1,600 tools, which can include virtually any resource that can be used in an experiment. These can be software applications like search, but they could be robots, lab hardware, or human technicians. The authors hope to create a standard for all tools used in any experiment.
Behind the news: SCP draws on earlier data management efforts for generalist AI agents and scientific inquiry. It extends MCP by enforcing tighter security, managing experiments, and providing specialized drivers for scientific tools. It also builds on earlier protocols for scientific research, including A-Lab (materials science), OriGene (biology), LLM-based approaches like Agent Laboratory, and agents for specific tasks like Biomni (biology hypotheses and analysis). SCP, however, aims to be more general than these field- or tool-specific resources, allowing researchers in a variety of scientific fields to standardize their methods and better foster multidisciplinary work.
Why it matters: Scientific research relies on both human and technology working in concert. SCP aims to standardize the connections between them. It can manage both simulated experiments that use only computing resources as well as physical ones that involve robots and other lab equipment. It also allows for better communication between institutions and disciplines by supporting dedicated servers on bigger networks. These distinctions (human/robot, digital/physical, disciplinary differences) are beginning to blur. SCP is a step toward that future.
We’re thinking: AI is poised to vastly accelerate scientific research. SCP offers a standardized way to connect specialized models, like AlphaFold, with systems that automatically generate hypotheses, such as AI Co-scientist, and robotic labs that test them, such as RoboChem. This automated experimental workflow has the potential to advance scientific discovery at machine speed.
Copilot’s Users Change Hour to Hour
What do users want from AI? The answer depends on when and how they use it, a new study shows.
What’s new: A Microsoft study reveals that people used Copilot differently late at night on their phones than during the workday on their laptops. Conversations that focused on productivity and career were more likely during the day and on desktop devices, and health, gaming, and philosophical questions dominated non-work conversations. As 2025 went on, more users asked the AI agent for personal advice.
How it works: Researchers analyzed anonymized summaries of 37.5 million Copilot conversations between January and September 2025 to study how customers used the system, making this the largest study of its kind to date. The authors conclude that AI has become more socially integrated, as users employ it in aspects of their lives beyond work.
- The authors examined a random sample of Copilot conversations by paid and unpaid users, excluding commercial, enterprise, and education accounts. Each conversation included timestamps and device type. The authors used AI tools to summarize roughly 144,000 conversations daily. They built classifiers to assign each summary a topic (like “technology”) and intent (like “seeking advice”), identifying about 300 topic-intent pairs.
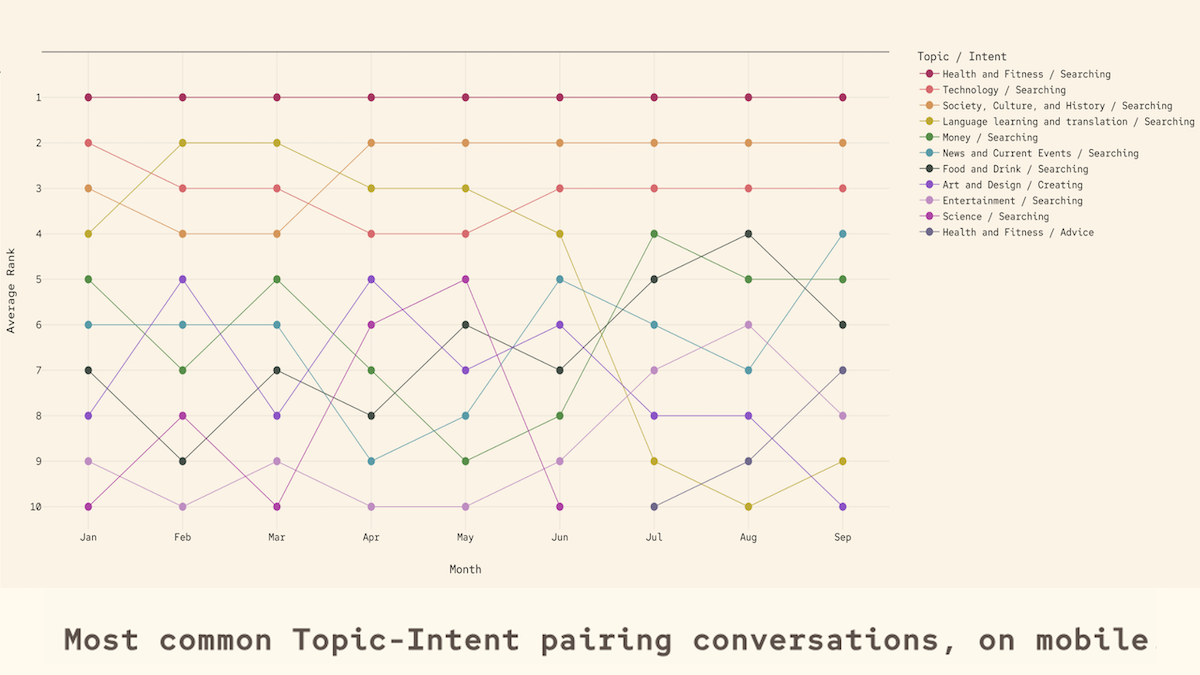
- The study ranks the frequency of topics and intents by time of year, time of day, and device type. The top 5 topics in order were (i) technology, (ii) work and career, (iii) health and fitness, (iv) language learning and translation, and (v) society, culture, and history. The top intents were (i) searching, (ii) seeking advice, (iii) creating, (iv) learning, and (v) technical support.
Analysis: Topics and intents differed depending on device used, time of day, and time of year.
- Users were much more likely to discuss health and fitness on mobile devices than desktops. Seeking advice about personal matters spiked near Valentine’s Day. Philosophical questions became more common later at night, while entertainment-related conversations plummeted during the workday.
- As the year progressed, topics and intents became less focused on work and technology and drifted towards social and personal matters. This shift suggested that the user base became both larger and less technical and/or users began using AI for both personal and professional matters.
Behind the news: Microsoft’s report follows similar studies by some of its AI rivals.
- In September 2025, OpenAI and Harvard released a study of ChatGPT use from 2022 to 2025. It showed that 30 percent of uses were related to work while 70 percent were related to non-work activities. In addition, the gender gap among users among users shrank steadily during that period.
- In January 2025, Anthropic’s study of Claude showed that the model’s user base focused on work, especially software development and text communications. A small but growing number of users engaged in games like Dungeons & Dragons and sexual roleplay (despite prohibition of that use by Claude’s terms of service).
Why it matters: The authors argue that the AI community may need to rethink chatbot design altogether. If users treat chatbots differently on mobile and desktop devices, AI builders would do well to design their systems to suit the devices that will deliver them. Application design is one way to accomplish this, but system prompts may be another. Desktop chatbots and agents can respond with more information-dense answers, guiding users to execute tasks, while mobile agents can offer shorter, more empathetic responses.
We’re thinking: Studies of chatbot usage conducted by different companies show different results. Perhaps each company’s users treat AI differently, so the results of any given study may not apply generally. That said, the Microsoft study suggests that the device used and the time when it’s used can have a big impact on what users want — important considerations for designing any application.
More Affordable Reasoning
One way to improve a reasoning model’s performance is to let it produce a longer chain of thought. However, attending to ever-longer contexts can become expensive, and making that attention more efficient requires changes to a model’s architecture. Researchers proposed a way to limit the cost of processing long chains of thought with just a bit of training.
What’s new: Delethink is a reinforcement learning (RL) method that trains large language models to periodically truncate reasoning tokens to a fixed maximum number. The authors include Milad Aghajohari, Kamran Chitsaz, Amirhossein Kazemnejad, and colleagues at Mila, Microsoft, McGill University, ServiceNow Research, Polytechnique Montréal, and Université de Montréal.
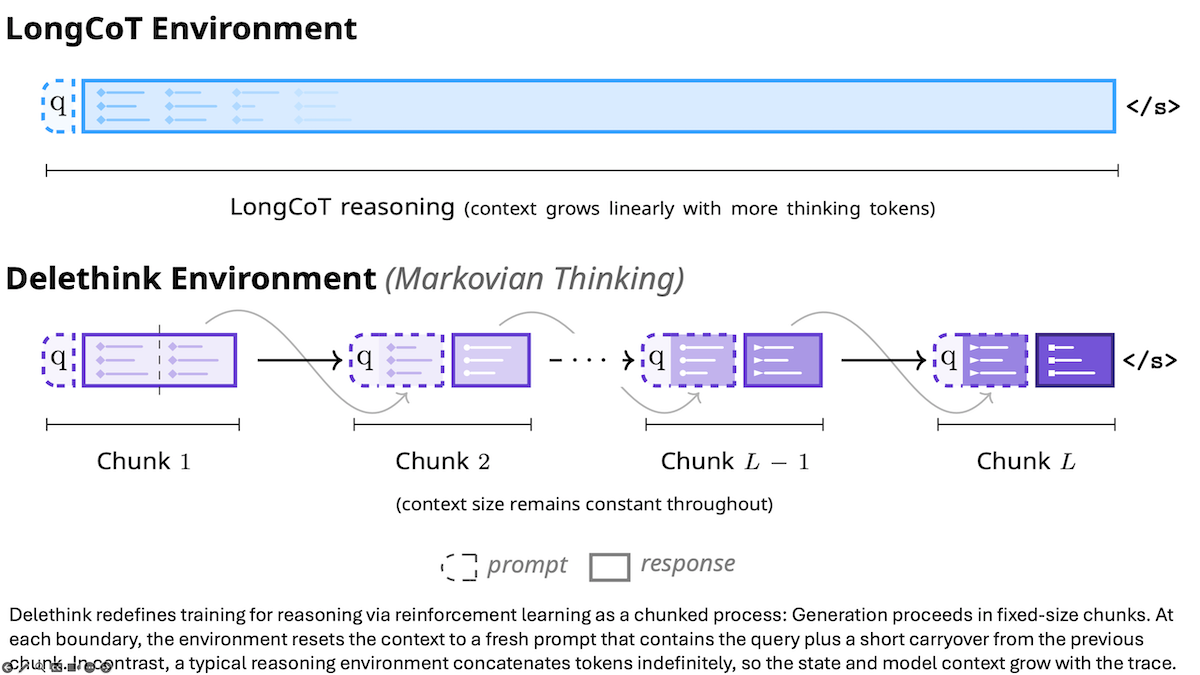
Key insight: Reasoning tokens typically accumulate within a large language model’s context window, where they consume quadratically more computation as the contents of the window expand. One way to counter this effect is to train the model to reason within a maximum context window size. In effect, as a model is reasoning, it can learn to replace its chain of thought periodically with its latest “thoughts” and then continue.
How it works: The authors fine-tuned R1-Distill 1.5B, a large language model, on math problems in the DeepScaleR dataset. They used a modified version of the reinforcement learning algorithm GRPO that trained the model to reason in 4,000-token chunks:
- Given a math problem, the model generated a chain of thought until it had either finished or filled the model’s context window with 8,000 tokens.
- If it didn’t finish its chain of thought, the authors replaced the context with the original query plus the last 4,000 tokens. Then the model continued to generate its chain of thought until it had either finished or the context window once again held 8,000 tokens.
- They repeated this process until the model had either finished its chain of thought or produced 24,000 reasoning tokens.
- Then the model attempted to solve the problem, receiving a reward for a correct solution.
Results: The authors compared their R1-Distill 1.5B models to the same model after fine-tuning on the same 24,000-token reasoning budget via using GRPO. They tested the models on reasoning budgets of 24,000, 96,000, and 128,000 tokens.
- With a budget of 24,000 tokens, their model matched or surpassed the baseline on all 3 math benchmarks tested. For example, on AIME 2025, Delethink (31 percent accuracy) outperformed the baseline (29 percent accuracy).
- Their model’s performance continued to improve as the authors increased the reasoning budget, while the baseline achieved much smaller gains. For instance, with a budget of 128,000 tokens, their model achieved 35 percent accuracy, while the baseline achieved 30 percent accuracy.
- The authors estimated that training their model with a 96,000-token reasoning budget would cost 7 H100-months, while the baseline would require 27 H100-months.
Why it matters: This work eases the quadratic compute barrier that can make extremely long reasoning computationally infeasible. While other methods, like linear attention, achieve the same result by changing the attention mechanism, Delethink restructures the reasoning process to limit processing regardless of a model’s attention mechanism. It opens a path to reason efficiently over longer contexts without requiring new model architectures.
We’re thinking: As the authors mention, most LLMs are pretrained using relatively short contexts. For example, Llama 3 models started pretraining with examples of 8,000 tokens. This may have made them good at processing inputs around 8,000 tokens long. That is to say, Delethink’s performance may have been helped by the fact that LLMs tend to be pretrained on short-context tasks.