

Vercel 深入研究了 AI 编码智能体如何学习特定框架的知识,特别是针对模型训练数据中不存在的 Next.js 16 API。他们对比了“Skills”(一种按需调用工具/文档的开放标准)与“AGENTS.md”(一种提供持久上下文的项目根目录 Markdown 文件)。结果令人惊讶:虽然 Skills 经常无法触发或需要脆弱的提示词,但嵌入在 AGENTS.md 中的 8KB 压缩文档索引却实现了 100% 的完美通过率。这种“被动上下文”方法之所以成功,是因为它消除了智能体的决策点并确保了信息的一致可用性。Vercel 现已将其集成到 CLI 中,允许开发者将版本匹配的压缩文档索引注入项目,从而强制实现“检索主导的推理”,而非过时的“预训练主导的推理”。
We expected skills to be the solution for teaching coding agents framework-specific knowledge. After building evals focused on Next.js 16 APIs, we found something unexpected.
A compressed 8KB docs index embedded directly in AGENTS.md achieved a 100% pass rate, while skills maxed out at 79% even with explicit instructions telling the agent to use them. Without those instructions, skills performed no better than having no documentation at all.
Here's what we tried, what we learned, and how you can set this up for your own Next.js projects.
Link to heading
The problem we were trying to solve
AI coding agents rely on training data that becomes outdated. Next.js 16 introduces APIs like 'use cache', connection(), and forbidden() that aren't in current model training data. When agents don't know these APIs, they generate incorrect code or fall back to older patterns.
The reverse can also be true, where you're running an older Next.js version and the model suggests newer APIs that don't exist in your project yet. We wanted to fix this by giving agents access to version-matched documentation.
Link to heading
Two approaches for teaching agents framework knowledge
Before diving into results, a quick explanation of the two approaches we tested:
-
Skills are an open standard for packaging domain knowledge that coding agents can use. A skill bundles prompts, tools, and documentation that an agent can invoke on demand. The idea is that the agent recognizes when it needs framework-specific help, invokes the skill, and gets access to relevant docs.
-
AGENTS.mdis a markdown file in your project root that provides persistent context to coding agents. Whatever you put inAGENTS.mdis available to the agent on every turn, without the agent needing to decide to load it. Claude Code usesCLAUDE.mdfor the same purpose.
We built a Next.js docs skill and an AGENTS.md docs index, then ran them through our eval suite to see which performed better.
Link to heading
We started by betting on skills
Skills seemed like the right abstraction. You package your framework docs into a skill, the agent invokes it when working on Next.js tasks, and you get correct code. Clean separation of concerns, minimal context overhead, and the agent only loads what it needs. There's even a growing directory of reusable skills at skills.sh.
We expected the agent to encounter a Next.js task, invoke the skill, read version-matched docs, and generate correct code.
Then we ran the evals.
Link to heading
Skills weren't being triggered reliably
In 56% of eval cases, the skill was never invoked. The agent had access to the documentation but didn't use it. Adding the skill produced no improvement over baseline:
Zero improvement. The skill existed, the agent could use it, and the agent chose not to. On the detailed Build/Lint/Test breakdown, the skill actually performed worse than baseline on some metrics (58% vs 63% on tests), suggesting that an unused skill in the environment may introduce noise or distraction.
This isn't unique to our setup. Agents not reliably using available tools is a known limitation of current models.
Link to heading
Explicit instructions helped, but wording was fragile
We tried adding explicit instructions to AGENTS.md telling the agent to use the skill.
Before writing code, first explore the project structure, then invoke the nextjs-doc skill for documentation.Example instruction added to AGENTS.md to trigger skill usage.
This improved the trigger rate to 95%+ and boosted the pass rate to 79%.
A solid improvement. But we discovered something unexpected about how the instruction wording affected agent behavior.
Different wordings produced dramatically different results:
Same skill. Same docs. Different outcomes based on subtle wording changes.
In one eval (the 'use cache' directive test), the "invoke first" approach wrote correct page.tsx but completely missed the required next.config.ts changes. The "explore first" approach got both.
This fragility concerned us. If small wording tweaks produce large behavioral swings, the approach feels brittle for production use.
Link to heading
Building evals we could trust
Before drawing conclusions, we needed evals we could trust. Our initial test suite had ambiguous prompts, tests that validated implementation details rather than observable behavior, and a focus on APIs already in model training data. We weren't measuring what we actually cared about.
We hardened the eval suite by removing test leakage, resolving contradictions, and shifting to behavior-based assertions. Most importantly, we added tests targeting Next.js 16 APIs that aren't in model training data.
APIs in our focused eval suite:
-
connection()for dynamic rendering -
'use cache'directive -
cacheLife()andcacheTag() -
forbidden()andunauthorized() -
proxy.tsfor API proxying -
Async
cookies()andheaders() -
after(),updateTag(),refresh()
All the results that follow come from this hardened eval suite. Every configuration was judged against the same tests, with retries to rule out model variance.
Link to heading
The hunch that paid off
What if we removed the decision entirely? Instead of hoping agents would invoke a skill, we could embed a docs index directly in AGENTS.md. Not the full documentation, just an index that tells the agent where to find specific doc files that match your project's Next.js version. The agent can then read those files as needed, getting version-accurate information whether you're on the latest release or maintaining an older project.
We added a key instruction to the injected content.
IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning for any Next.js tasks.Key instruction embedded in the docs index
This tells the agent to consult the docs rather than rely on potentially outdated training data.
Link to heading
The results surprised us
We ran the hardened eval suite across all four configurations:
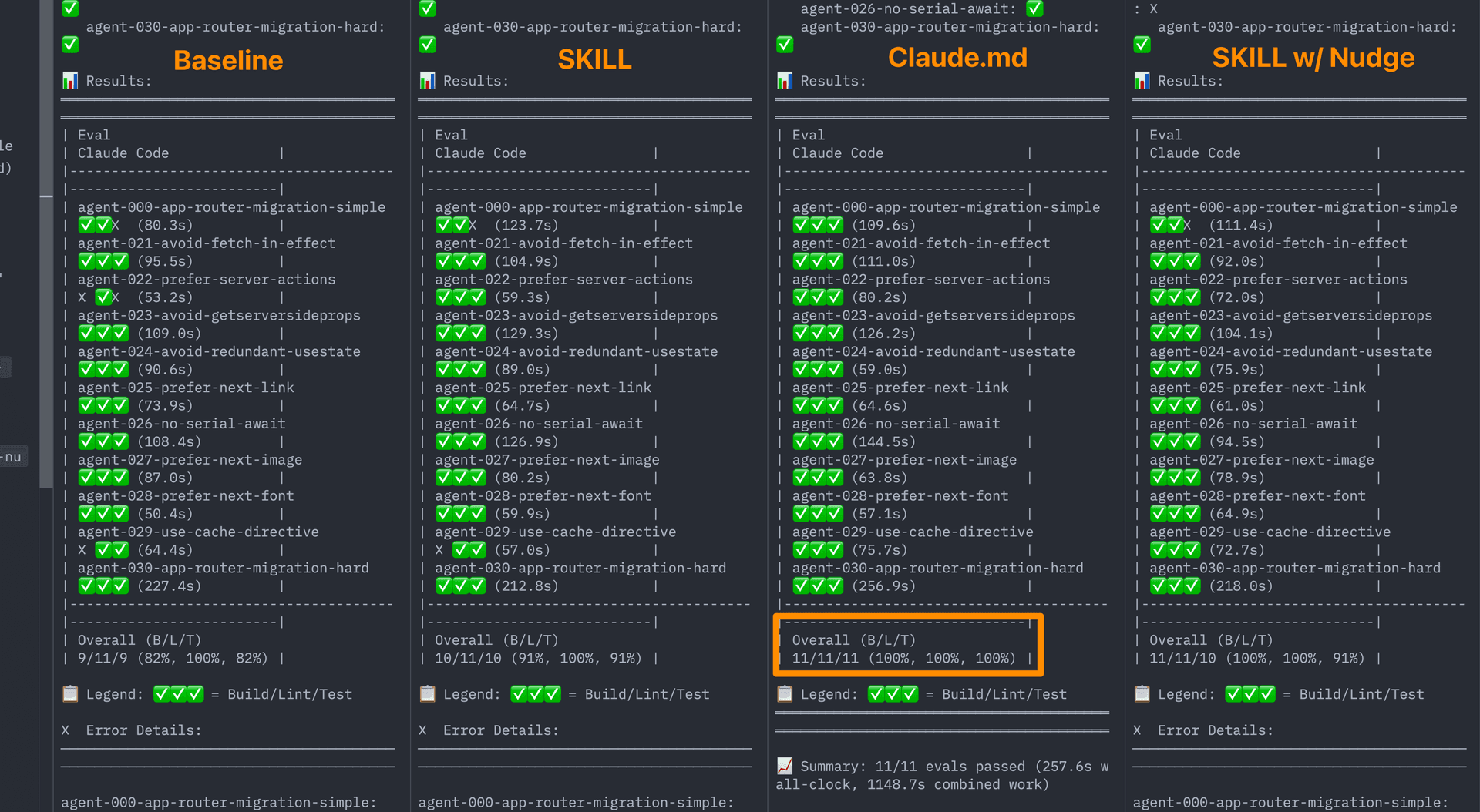
Final pass rates:
On the detailed breakdown, AGENTS.md achieved perfect scores across Build, Lint, and Test.
This wasn't what we expected. The "dumb" approach (a static markdown file) outperformed the more sophisticated skill-based retrieval, even when we fine-tuned the skill triggers.
Why does passive context beat active retrieval?
Our working theory comes down to three factors.
-
No decision point. With
AGENTS.md, there's no moment where the agent must decide "should I look this up?" The information is already present. -
Consistent availability. Skills load asynchronously and only when invoked.
AGENTS.mdcontent is in the system prompt for every turn. -
No ordering issues. Skills create sequencing decisions (read docs first vs. explore project first). Passive context avoids this entirely.
Link to heading
Addressing the context bloat concern
Embedding docs in AGENTS.md risks bloating the context window. We addressed this with compression.
The initial docs injection was around 40KB. We compressed it down to 8KB (an 80% reduction) while maintaining the 100% pass rate. The compressed format uses a pipe-delimited structure that packs the docs index into minimal space:
[Next.js Docs Index]|root: ./.next-docs|IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning|01-app/01-getting-started:{01-installation.mdx,02-project-structure.mdx,...}|01-app/02-building-your-application/01-routing:{01-defining-routes.mdx,...}Minified docs in AGENTS.md
The full index covers every section of the Next.js documentation:

The agent knows where to find docs without having full content in context. When it needs specific information, it reads the relevant file from the .next-docs/ directory.
Link to heading
Try it yourself
One command sets this up for your Next.js project:
npx @next/codemod@canary agents-md
This functionality is part of the official @next/codemod package.
This command does three things:
-
Detects your Next.js version
-
Downloads matching documentation to
.next-docs/ -
Injects the compressed index into your
AGENTS.md
If you're using an agent that respects AGENTS.md (like Cursor or other tools), the same approach works.
Link to heading
What this means for framework authors
Skills aren't useless. The AGENTS.md approach provides broad, horizontal improvements to how agents work with Next.js across all tasks. Skills work better for vertical, action-specific workflows that users explicitly trigger, like "upgrade my Next.js version," "migrate to the App Router," or applying framework best practices. The two approaches complement each other.
That said, for general framework knowledge, passive context currently outperforms on-demand retrieval. If you maintain a framework and want coding agents to generate correct code, consider providing an AGENTS.md snippet that users can add to their projects.
Practical recommendations:
-
Don't wait for skills to improve. The gap may close as models get better at tool use, but results matter now.
-
Compress aggressively. You don't need full docs in context. An index pointing to retrievable files works just as well.
-
Test with evals. Build evals targeting APIs not in training data. That's where doc access matters most.
-
Design for retrieval. Structure your docs so agents can find and read specific files rather than needing everything upfront.
The goal is to shift agents from pre-training-led reasoning to retrieval-led reasoning. AGENTS.md turns out to be the most reliable way to make that happen.
Research and evals by Jude Gao. CLI available at npx @next/codemod@canary agents-md